本文将介绍Interspeech 2017上关于语音唤醒技术的几篇文章。
相应分享视频链接:
首先,什么是语音唤醒?
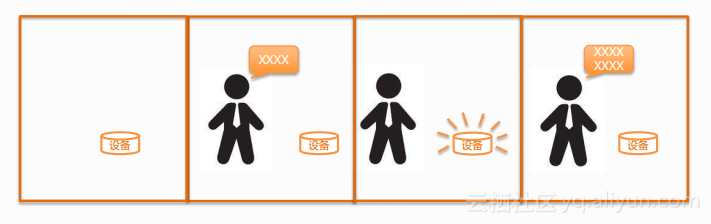
上面的四幅图表现设备从休眠到唤醒的过程:首先,设备需要被开启,自动加载好资源,这时它处于休眠状态。当用户说出特定的唤醒词时,设备就会被唤醒,切换到工作状态等待用户接下来的指令。这一过程中用户不需要用手接触,直接可以用语音进行操作,同时利用语音唤醒的机制,设备不用实时地处于工作的状态,从而节省能耗。
语音唤醒的应用领域比较广泛,例如机器人、手机、可穿戴设备、智能家居、车载等。几乎很多带有语音功能的设备都会需要语音唤醒技术作为人和机器互动的一个开始或入口。不同的产品会有不同的唤醒词,当用户需要唤醒设备时需要说出特定的唤醒词。大部分的唤醒词都是三到四个音节,音节覆盖多,音节差异大,相对唤醒效果会比较稳定。
对于一个唤醒效果好坏的判定,主要有召回率、虚警率、实时率和功耗四个指标。召回率表示正确被唤醒的次数占总的应该被唤醒次数的比例。虚警率表示不该被唤醒却被唤醒的概率。召回率越高虚警率越低就表示唤醒的性能越好,这两个指标的关系经常是一个相对关系,即一个指标的上升对应另一个指标的下降。从用户体验的角度来讲,实时率可以表现为设备反应的速度,唤醒技术对设备的反应速度要求很高。另一个指标是功耗,由于很多设备依靠电池或者是充电式的,具有低能耗才能保证设备较长时间的工作不需要充电,实际上,不同方向的产品使用场景不同,相对它的技术难点是有很大区别的,例如,车载环境下唤醒的难点在于它周围环境的噪声比较大,因此噪声环境下的召回率和虚警率就变得很重要;智能家居中的智能音箱、智能电视等也会受到环境噪声的影响,这时的噪声主要是人的声音,即其他人说话声音对本人说话声音的影响。而且多数的智能家居是充电后使用的,低功耗也成为一个非常重要的指标。唤醒其实是与实际结合非常紧密、非常重视用户体验的一种任务。
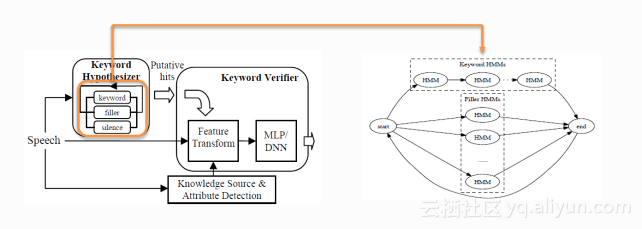
唤醒可以看成是一种小资源的关键词检索任务,其中小资源是指计算资源比较小和空间存储资源比较小,因此它的系统框架跟关键词检索的系统会有一定的区别,目前常用的系统框架主要有Keyword/Filler Hidden Markov Model System和Deep KWS System两种。
第一种被称为基于隐马尔科夫模型的Keyword and Filler系统,这类系统的关键是上图中左侧的解码模块,它与语音识别器中的解码器类似,也是通过维特比算法来获取到最优的路径,但是与语音识别中LVCSR(大规模词表语音识别)系统的区别在于解码网络具体的构建,语音识别中的解码网络包含所有词典中的词汇,而唤醒的解码网络如上图右侧包含了Keyword和Filler的途径,除了关键词以外的词汇都包含在Filler路径当中,不是每一个词都会有相应的路径,这样的网络会比语音识别的网络小很多,有针对性地对关键词进行解码,可选的路径就少了很多,解码的速度也会得到大幅度的提升。对于解码出来的候选再作一个判断,就完成这样一套技术方案的整体构架。
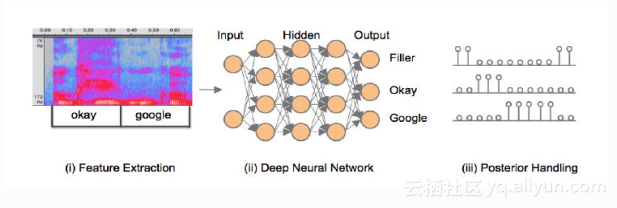
第二种系统不再采用解码这样一个步骤,直接是由端到端的模式,即输入是语音,输出直接是关键词。这样的系统包括三个部分:如上图,第一步是特征的提取,第二步通常是一个神经网络,它的输入是语音特征,输出是各个关键词和非关键词即Filler这样一个后验概率。由于第二步的网络是以帧为单位输出后验值的,就需要第三步对后验值以一定的窗长进行平滑,平滑后的后验值如果超过一定的阈值会被认为是唤醒了。
下面介绍Interspeech 2017上关于语音唤醒技术的文章,其中挑选了三篇跟大家分享。
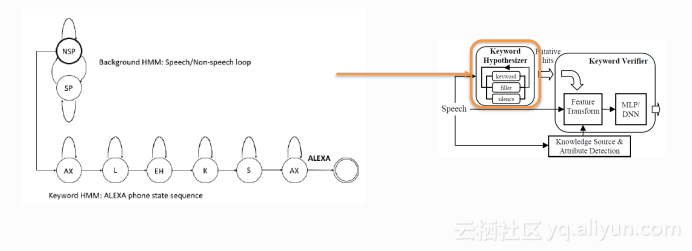
第一篇如上是来自于Amazon的一篇文章,它的系统架构采用了上文介绍的第一类系统,也就是需要有解码的系统。这篇文章的关键点在于对解码模块尝试使用了TDNN(Time Delay Neural Network)的声学模型,同时为了提升TDNN的性能以及减少TDNN的计算量,使其能够满足实际使用的实时率要求也做了一系列的优化。
在这一架构当中解码模块是比较重要的,如上图左侧画出了系统的解码网络,分为ALEXA关键词路径和Filler路径,其中NSP表示Non-speech(非语音)Filler路径,SP表示Speech(语音)Filler路径。图当中的每一个圆圈都是一个隐马可夫模型,在建模单元上,下面的关键词是采用了三状态的隐马可夫模型对音素进行建模,而Filler部分采用了单状态的隐马可夫模型进行建模。解码过程中,当有token走到了关键词的词尾节点时需要进行一个判断,此时采用关键词与filler的声学模型得分之比作为一个衡量标准,当它大于一定阈值的时候才会进入到下一个模块当中。
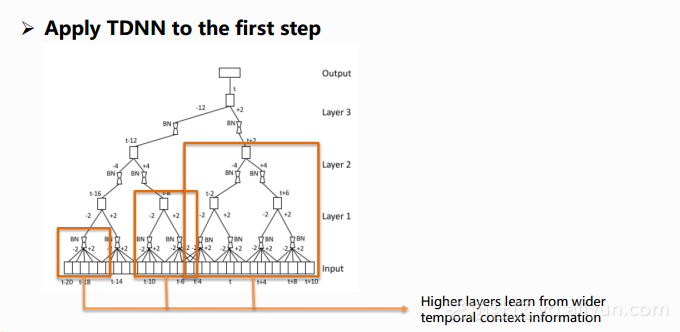
文中采用TDNN指的就是对于图左侧的隐马可夫模型的一部分即发射概率采用TDNN来进行建模。TDNN的学习需要用到前后帧所保留下来的信息,同时还需要照顾到一些时间轴的信息,所以它的结构图跟我们平时看到的DNN结构图画法上有比较大的区别。下图中的小黑框指的是网络的隐层,这个图表示的就是时间为t的那一帧在时间维度上的一个网络结构。从图中的橙色框可以看出,越深的层它能够学习到的上下文信息是越宽的,从左往右逐个加深,对应的输入特征也是变得越来越宽的过程,对于时间为t这一帧的建模实际上用到的是t-20到t+10这30帧的一个输入特征,这个长度可以通过调节变得更加长,这种长时的信息学习是DNN不能够做到的,所以说TDNN主要的优势在于能够学习和处理更长的上下文信息。
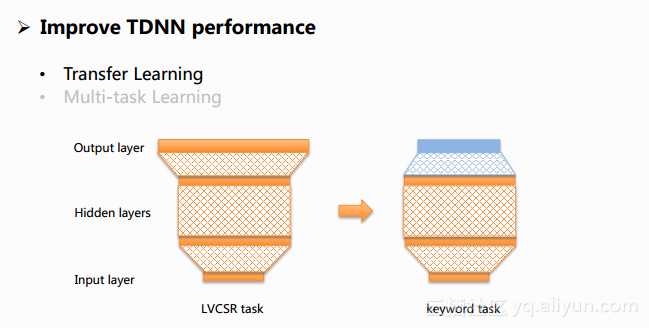
为了能够得到一个更好的TDNN的效果,文中采用了Transfer Learning和Multi-task Learning两个方法。
Transfer Learning是一种在机器学习中广泛使用的方法,核心的意思是将从一个相关任务学习到的知识迁移到当前的任务当中来,对于文章中的任务来说采用的方法就是先训练一个LVCSR的网络,之后对于唤醒任务的网络,它的隐层参数就用LVCSR这样的网络参数作为初始值,再进行唤醒网络的训练,这样做的好处就是使得唤醒任务的网络能获得一个更优的初始化,从而有助于它最终收敛到一个更优的局部最优点上。
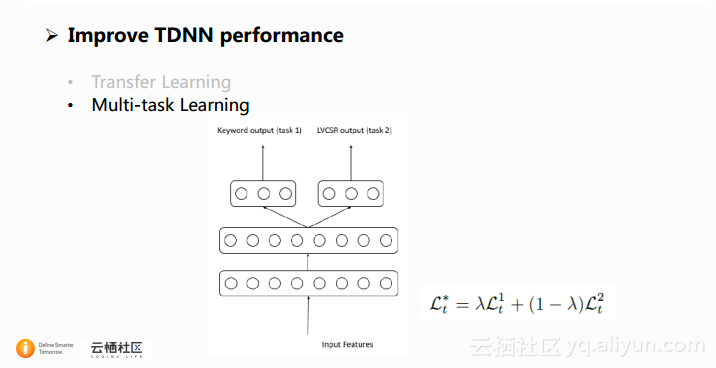
另一个提升TDNN性能的方法是采用共享隐层的结构进行多任务的学习,也就是Multi-task Learning。在这篇文章当中,从上面的结构图中可以看到,网络学习的一个任务是关键词任务,另一个是LVCSR任务,两个任务共享了输入层和大部分的隐层,训练中的目标函数如公式中展示的,是两个任务的加权平均,其中任务的权重可以自行调节。这个网络的优点在于最终使用的时候会将只跟LVCSR相关的这些节点从网络中剥离,因此网络的使用跟之前的常用的网络一样,比较简单。
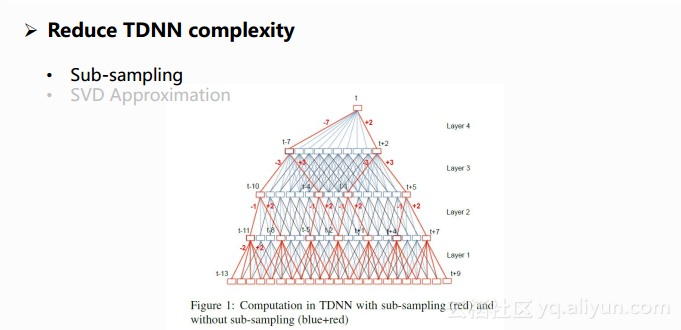
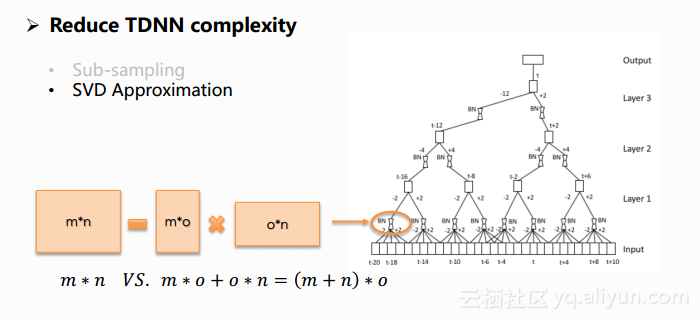
由于TDNN比DNN的计算量大很多,为了能够满足实际使用的需求,文章中采用了一些方法来降低TDNN的计算量。一种方法叫做Sub-sampling,下图中所有的线是原始TDNN的一个形态,是一个全连接的网络,但事实上相邻时间点所包含的上下文的信息是有很大部分重叠的,因此可以采用采样的方法只保留图中部分的连接,比如像图中保留了红色线的部分,实验中显示出这样的采样可以获得与原始模型近似的效果,同时能够大大减少模型的计算量。
另外一个降低计算量的方法是采用奇异值分解。如下图,将一个参数矩阵转换成两个参数矩阵相乘,进行完奇异值分解后,奇异值会从大到小进行排列,其中o表示保留下来的奇异值个数。在很多情况下,前10%甚至1%奇异值的和就占据了全部奇异值总和的99%以上,因此在这样的分解中去合理选择o不会给模型带来性能的损失,甚至这样的结构调整会使得模型的结构更加合理,从而获得一个更好的收敛点,更最重要的是,它大大减少了模型的计算量。下图中列出了矩阵奇异值分解前和后计算量的计算公式,等号前面是一个矩阵的计算量,后面相当于两个矩阵的计算量,大部分情况后者的计算量都会远小于前者,o越小时,差距会越大。文章使用的是将隐层的参数矩阵去做这样的一个分解,使得TDNN的计算量得到缩减。
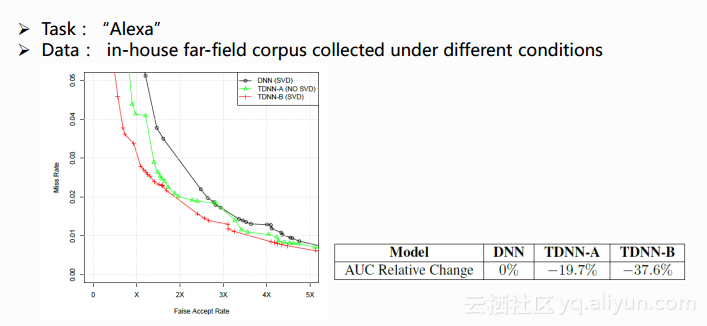
下图为它的一些实验结果,文章中的实验使用的关键词是”Alexa”,训练以及测试的数据是在不同条件下采集到的房间内的远场数据,文中提到他们采用了充足的训练开发以及测试数据。其中左图的横坐标表示虚警率,纵坐标表示没有召回的概率(1-召回率),显示的三条曲线叫作ROC曲线,ROC曲线的位置越低表示性能越好。用于对比的BaseLine是一个做了SVD的DNN模型,即图中的黑线所示,相比较的是TDNN的结果,即图中的绿线和红线,绿色表示没有做SVD的,红色是做了SVD的。从图中可以看出TDNN会比DNN性能好,而后进一步做SVD会给TDNN带来进一步的性能提升。右边的表格列出的是AUC(Area under Curve)的结果,即ROC曲线下面的面积,面积越小表示性能越好,而从表格中可以看出TDNN相对于DNN有了一个很大的提升。
第二篇文章如上,来自于百度,采用的框架是本文之前介绍的第二种系统框架Deep KWS System。此系统采用端到端模式,其中最重要的一部分是神经网络,本篇文章采用了CRNN的网络结构,同时为了减小模型的计算量,文章中探索了不同模型结构和参数来获得一个相对更优的效果。CRNN是将CNN和RNN融合在一个网络当中,CNN的优势在于挖掘局部的信息,而RNN的优势在于学习长时的上下文信息,两者的结合可以起到互补的作用。之前百度有在LVCSR任务上采用了这样的模型,在采用CRNN的同时使用CTC目标函数进行训练,在语音识别的任务上获得了很好的效果,他们希望把这样的模型引入到唤醒任务当中,但是CTC目前都是在模型规模比较大、数据量比较大的情况下得到较好的效果,这一点并不适用于唤醒的任务,而且文章中在唤醒的实验上也表明了目标值采用CTC没有获得预期的效果,因此在本文中实际依然采用交叉熵作为目标函数。
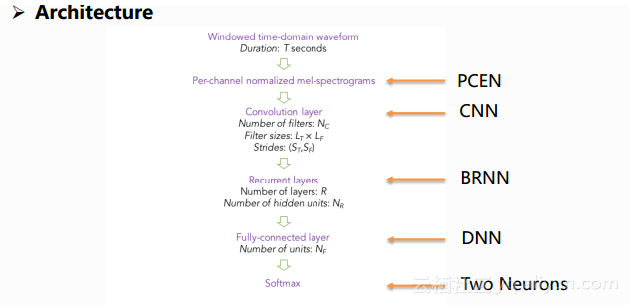
上图是他们最终使用的结构,图中上下两端分别表示输入和输出,输入的直接是语音,图中采用PCEN的语音特征直接加在了网络结构当中,此特征在他们的其它论文当中有相应的详细阐述,它具有比较好的抗噪的能力,后面的隐层依次包含了CNN、双向的RNN和DNN,输出层有两个节点,表示是否是关键词。这样的一个结构包含了很多可以手工进行调整的参数,以及RNN节点结构的选择。文章中给出了很多组参数的对比结果,以及像RNN节点是用LSTM还是GRU等的对比。
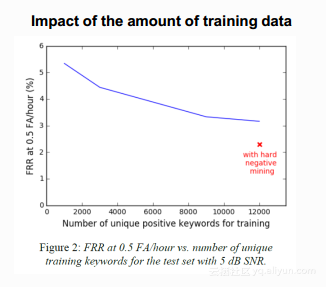
文章中的实验采用了单一的关键词”TalkType”,训练和测试数据来源于5000多个说话人,文中做出了非常详尽的实验。其中之一如下图是分析数据量对于性能的影响,图中横坐标表示正样本的条目数,纵坐标表示每小时应该被唤醒却没有被唤醒的次数。图中的蓝线表明正样本数据的增加对数据的影响,随着正样本数目的增加对于模型是有好处的,但是当到达一定程度时就会达到饱和,红色的×表示加入了各种负样本,可以看到相对于正样本的增加,负样本的增加能给模型带来更大程度的提升。
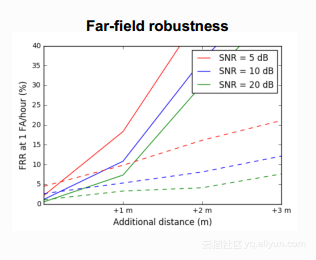
数据对于性能的影响在另外一个实验当中也得到了体现。下图表示是对于远场鲁棒性的实验。实验中原有的测试数据加上了混响来模拟不同远度的测试数据,横坐标表示的是模拟发生源与设备的距离,纵坐标表示每小时漏唤醒的次数。此图中漏唤醒的范围明显比上一个图的漏唤醒范围大,特别是在距离比较远的情况下恶化是比较明显的。图中实线表示训练数据不做特殊处理的一个结果,可以看出在距离大于1m后,它的性能恶化得比较快,很大的原因是由于训练和测试数据的不匹配,而虚线表示训练数据卷积上各种空间的冲激响应之后扩展了原有的训练数据,这里的冲激响应与测试数据当中用到的不同,虽然不同但是虚线明显平缓了很多,特别是在距离比较远的情况下,性能的提升是非常明显的,文中给出的结论就是,训练数据应该谨慎地选择,要能够反映实际的应用场景。
另外,文章中做了一个CRNN和CNN对比的实验。当性噪比比较小的时候CRNN优于CNN,随着性噪比的增大,两者之间的差距变得越来越小。CRNN和CNN的差别就在于RNN,因此得出结论,RNN对于性噪比小,即噪声比较大的情况是非常有帮助的。同时在文章的最后给出了综合的结果如下图,在每小时误唤醒为0.5个的条件下,不同性噪比上得到的性能。
第三篇文章如上,来自于佐治亚理工的,主要针对关键词的检索,本文之前提到唤醒可以看成小资源的简化版的关键字检索,而这篇文章对于唤醒任务同样具有借鉴意义。由于不受资源的限制,文章中关键词检索采用的解码网络就是一完整的LVCSR解码网络,这篇文章的主要工作在于对用于解码的模型的改进,它采用BLSTM的模型结构,同时使用Non-Uniform MCE这样鉴别性的训练准则进行模型训练,他们早期在DNN上尝试使用这样的准则。图中下侧列出了他们之前发表的一些文章。
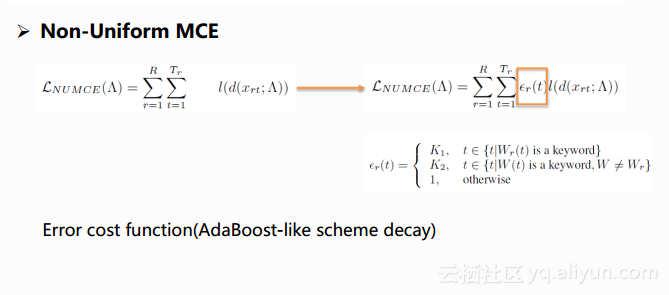
首先,他们之所以使用BLSTM的原因是BLSTM模型能够学习长时的上下文信息。MCE(最小分类错误)是一种鉴别性训练准则,有助于提升模型对于相似词的鉴别能力。Non-Uniform MCE的提出是因为作者发现系统当中的一个问题,事实上这一问题也存在于第一类唤醒系统当中。在第一类需要解码的唤醒系统当中,解码模块用到的声学模型训练是针对所有词的,这一目标与唤醒系统的目标存在不一致,唤醒系统更在意的是关键词的参数指标,因此作者提出了Non-Uniform MCE的准则,更偏重于模型对于关键词的训练。
如上图,我们可以看到第一个公式是一个帧级别的鉴别性的函数,其中Xrt表示第r句话第t帧的特征,SWt 表示Xrt的标注,前一个p是声学概率,后一个p是语言模型概率。第二个公式是对误分类度量的公式,第三个公式是训练神经网络所需要的目标函数。作者的优化在于对目标函数增加了一部分,称为错误代价函数,加入这样一个代价函数的优点在于它使得目标函数可以对不同类型的错误给予不同程度的惩罚值。在本文的任务当中,对于关键词分类的错误就会受到更加严厉的惩罚。在实际使用当中,随着迭代的进行,误差函数是会产生变化,会以类似AdaBoost的方法不断地乘以一个小于一的系数来减小它对于整个系统的训练作用。有了目标函数,剩下的工作就是bp算法的推导,只要推导参数更新的公式就可以进行神经网络的训练了,具体的推导在文章中也有详细的展现。
此外,在训练过程中作者对于因素错误率高的词会人为地去提升它的自然值,这也会为系统带来进一步的提升,同时作者也提到了这样的方法实际上相当于采用了更多容易产生混淆的一个数据,相当于一个数据复制的过程。
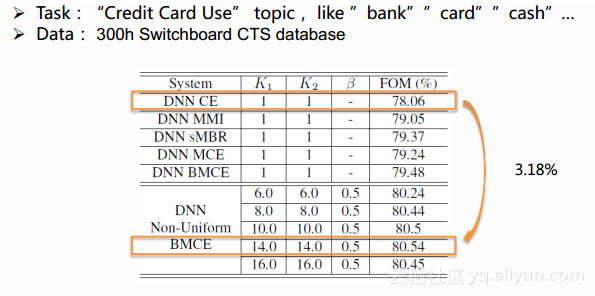
最后一个实验是在Switchboard 300小时上进行的关键词任务,其中使用的关键词比较多,主题都是关于信用卡的使用。如下表格表示,相当于在DNN上做的实验结果,不同模型的性能采用FOM指标进行表示,FOM越高表示性能越好,表中列了许多不同准则训练得到的DNN性能结果,第一个CE表示交叉熵的准则,它是一个产生式的训练准则,后面的MMI、sMBR、MCE、BMCE都是鉴别性的准则。从表中可以看出,几种鉴别性的准则都会比CE的方式好一些,最后一种是作者文章中提到叫作Non-Uniform BMCE的准则,通过调整后面K1、K2的参数可以得到良好的性能。
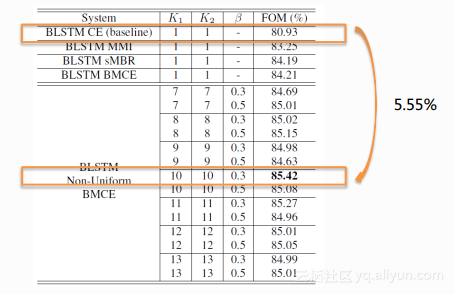
下面这张表格是在BLSTM上做的实验,通过上下两张表格对比,使用BLSTM整体会比用DNN的性能更好一些,但也需要付出代价,因为BLSTM相应的实时率计算量比DNN大很多。下面的表格同样采用了不同的训练准则,在BLSTM下采用作者新提出的方法,经过参数调整后最好的结果相对它的CE的BaseLine会有相对5.55%性能的提升。
以上即为本人对Interspeech 2017上其中关于语音唤醒技术的三篇文章的理解与经验分享。